医学多模态论文合集
Towards Generalist Foundation Model for Radiology by Leveraging Web-scale 2D&3D Medical Data
https://arxiv.org/pdf/2308.02463
code
内容
提出了RadFM,放射学基础模型 divide-and-conquer 分治
构建多模态数据集MedMD,先用MedMD预训练再用从中提炼的RadMD微调
提出RadBench评估基准
数据集组成
1.interleaved dataset 从医学论文中提取出来图片和描述性文字
2.visual-language instruction tuning dataset
3.Radiology Multimodal Dataset
训练方法和任务
预训练使用加权的负对数似然方法,对于UMLS(Unified Medical language system)中的词,设置更高的权重,对image token不设置权重
对于visual instruction dataset有五种任务,有些包含(是否/开放性回答)结合的instruction
modality recognition
disease diagnosis
visual question answering
report generation
rational diagnosis
模型架构处理
全部使用3D数据输入,对于2D复制切片成3D(pad into 4 slices on the depth channel)
图片先用ViT得到特征,然后嵌入感知机(perceiver)里面得到固定大小的token(32*5120),这里在图片前后加上image这样的special token分割图片和文本
4个epoch预训练,4个epoch微调,其中第一个epoch固定模型参数,训练perceiver
收获
1.可考察的VQA任务
2.生成QA数据的prompt
3.考察文本生成效果的benchmark BLEU, ROUGE, UMLS_Precision, UMLS_Recall, BERT-Sim
4.可以用来对比的基线模型
Large-scale Long-tailed Disease Diagnosis on Radiology Images
https://arxiv.org/pdf/2312.16151
建立一个基础放射学诊断模型,但只输入图片做分类
理想的放射诊断系统期望能够综合分析任何解剖区域的任意历史扫描和各种疾病的成像模式的组合
问题建模
建模成一个分类问题
标签呈现为扫描数和疾病标签的组合
数据集RP3D-DiagDS
1.模态覆盖度 有部分病例有多种模态的图像
2.解剖覆盖范围
3.疾病覆盖度 非常长尾分布
消融实验
消融实验目的是探索最好的模型架构和参数配置
选择了resnet和ViT结合的视觉编码器架构
设置评估benchmark
1.融合方式:
early fusion和late fusion两种,最后选择了early fusion
解释一下:
early fusion将来自不同图像的视觉特征进行融合,然后再进行分类。也就是说,模型会先将每个图像的视觉特征提取出来,然后把这些特征结合起来,形成一个整体的病例特征,最后用这个特征来进行疾病分类
late fusion在每个图像的视觉特征被提取出来之后,分别对每个图像进行分类,然后将所有的分类结果进行融合,最后得到最终的病例分类结果
fusion module从mean pooling,max pooling和random picking选取max pooling,在附录B中有对比
2.知识增强
3.其他?
方法
1.先用visual encoder处理2D或者3D扫描
图片C x H x W x D 其中2D和3D的区别在最后一个维度D上
这里先用normalization module转换2D和3D输出到一个映射上,然后一起传入shared encoding module
normalization module和shared encoding module有3种选择组合方式
2.基于transformer encoder的融合方式得到诊断结果
加class token和modality embedding和知识增强,然后取第一维的fused embedding(也可能取平均?看一下答案,不过一般加class token分类都是取第一维)
总体方法如下图所示: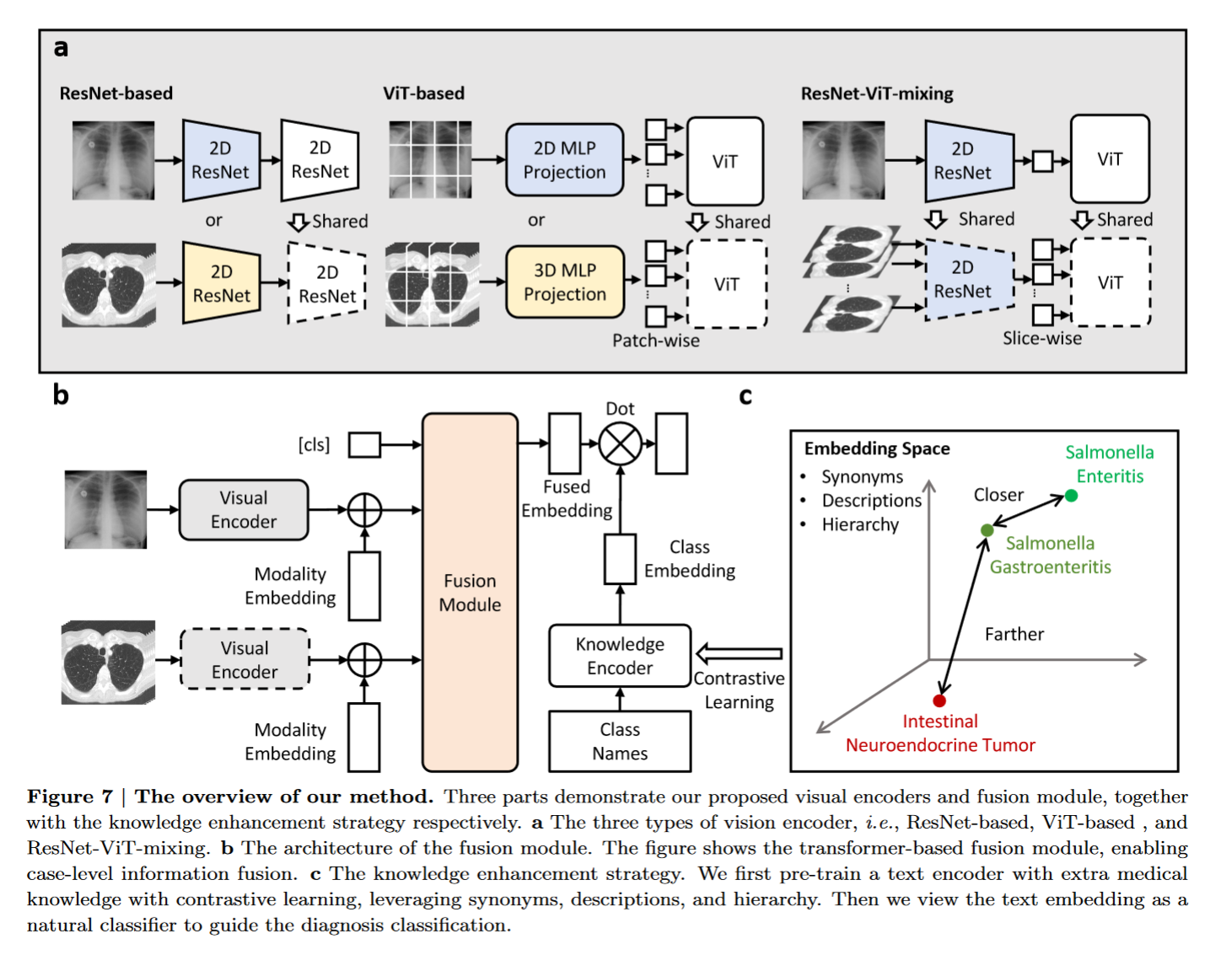
tips: 这里visual encoder中使用的ViT和第二阶段使用transformer encoder是两码事,不要搞混
问题和疑惑
1.图7a的resnet-based 3D是不是画错了
2.3D扫描深度16,32指的是什么 参考11.3
3.Section B中 early fusion和late fusion
这篇论文细节太多,要慢慢看了
收获
1.数据集RP3D-DiagDS(是否开源?因为数据处理做得多,质量高)
2.融合方式,视觉编码器选择
Improving Segment Anything on the Fly: Auxiliary Online Learning and Adaptive Fusion for Medical Image Segmentation
https://arxiv.org/pdf/2406.00956
code
增强Segment Anything Model在下游任务分割的能力,尤其是医学图像
提出方法: AuxOL
方法概述: 借助online machine learning,在与SAM结合的推理过程中使用更小的辅助模型Aux,辅助模型调整SAM的输出,同时进行在线权重更新
使用场景和优势: 医院正常工作的时候可以不断引入人类反馈更新模型,而不是部署以后就参数固定。同时,SAM模型参数固定,更新小模型Aux计算量少。
related work
1.SAM
2.针对下游任务的训练
3.Online Machine learning
方法
模型架构: 辅助模型Aux的架构可以是U-Net,并且可以使用已经在ImageNet上预训练的encoder权重和随机初始化的decoder
训练数据: 图像$x_t$和这个图片的一堆prompt(实际上就是对图片标注一堆b-box或者中心坐标的数据)$p_{j}^t$
流程:
1.如果prompts中给了b-box,直接裁剪; 如果prompts中给了中心坐标,结合一些图片经过SAM后得到的logits矩阵裁剪
2.裁剪完的原始图片送入Aux得到logits矩阵,与最开始经过SAM的logits融合得到输出图片?
3.如果有Human expert(HE),就做修改(怎么个修改),并与Aux输出的矩阵做计算,得到loss(loss的计算方式?)更新Aux模型; 否则用伪标签或者自监督学习计算loss
总体方法如下图所示,还是非常直观的: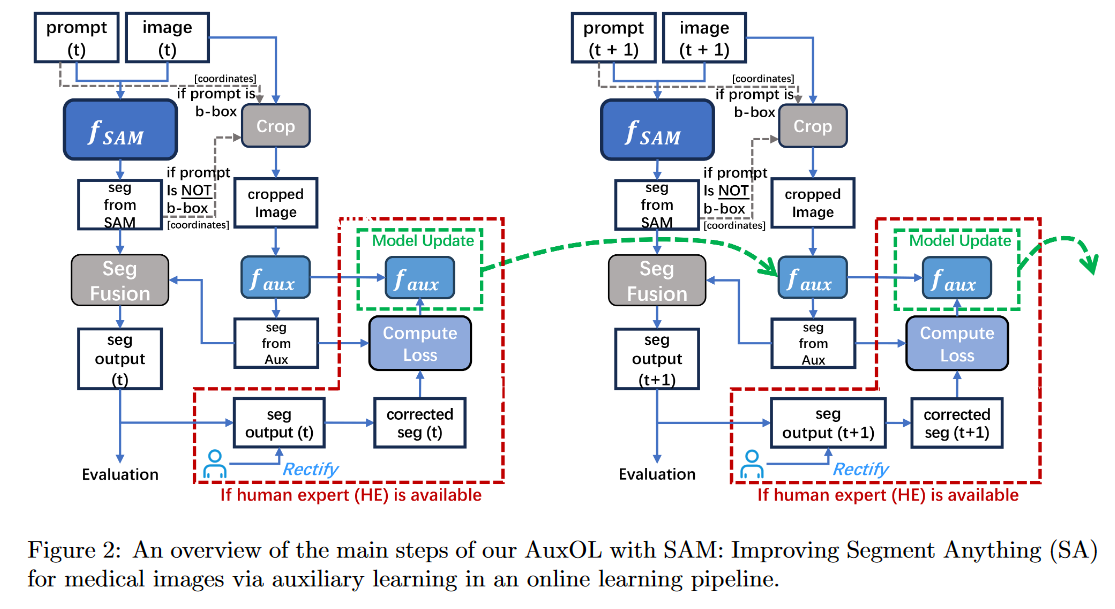
其他: 在线批量BP —> 有个小trick 保持batch_size不变,对比loss大小决定要不要替换batch_size里面的元素
提升:
1.将融合的$\alpha$值做自适应调整 —> 利用到了DSC相似系数 这里的自适应调整可能和在线学习有关?
2.给Aux模型输入的方式进行修改,把s概率矩阵和裁剪的原始图片一起输入; 潜在问题就是s概率矩阵可能很离谱,而在原始的方法有prompt提示,可以初步裁剪出相对来说还可以的图片区域; 对b-box提供s和x,对中心坐标只提供x 不过这样的话这里的model架构会不会有变化?
实验
使用了SAM-H和SAM,U-Net,使用DSC和HD指标评估
表明部分的人类专家反馈可以得到更好的分割改进(0%-25%-50%-100%) 并且提出实际场景对于DSC值低的进行修正
对已经适应下游任务的SAM来适应别的任务? 这里还需要看一些相关论文才能理解
对Online-batch和$alpha$分别做消融实验
问题和疑惑
1.Introduction中第一段说的“对于每个不同的医学图像分割任务,可能需要应用全会话离线微调和/或适应。虽然可以做到,但它会产生大量的计算和时间成本,并且由于每项任务都需要新的离线训练而变得僵化。”原因
2.$f_{aux}$和$f_{SAM}$经过的图片融合是怎么样的过程,因为分别的图片大小应该不同吧
3.$f_{aux}$和$f_{SAM}$得到的logits是概率图吗?
4.流程图中给了prompt告诉了我们中心坐标或者b-box,但实际情况一张图片给出来,没有标注怎么办?这里的问题没有理解清楚
收获
1.SAM-H和SAM model
2.在线学习算法以及辅助模型与SAM的融合方式
3.DSC和HD指标
4.SAM下游任务的适应方法 MSA和SAMed
M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models
https://arxiv.org/pdf/2404.00578
code
主要是推进3D医学图像
数据
1.image-text pair data
2.instruction-response pair data
其中包含构造VQA数据和定位切分(position and segmentation)数据
VQA数据使用qwen72B在平面、阶段、器官、异常和位置这5个方面生成选择题
需要构造3D image-mask-text pair 三种方式中前两种已经标注了掩码,最后一种没有掩码并需要专家标注
具体流程如图: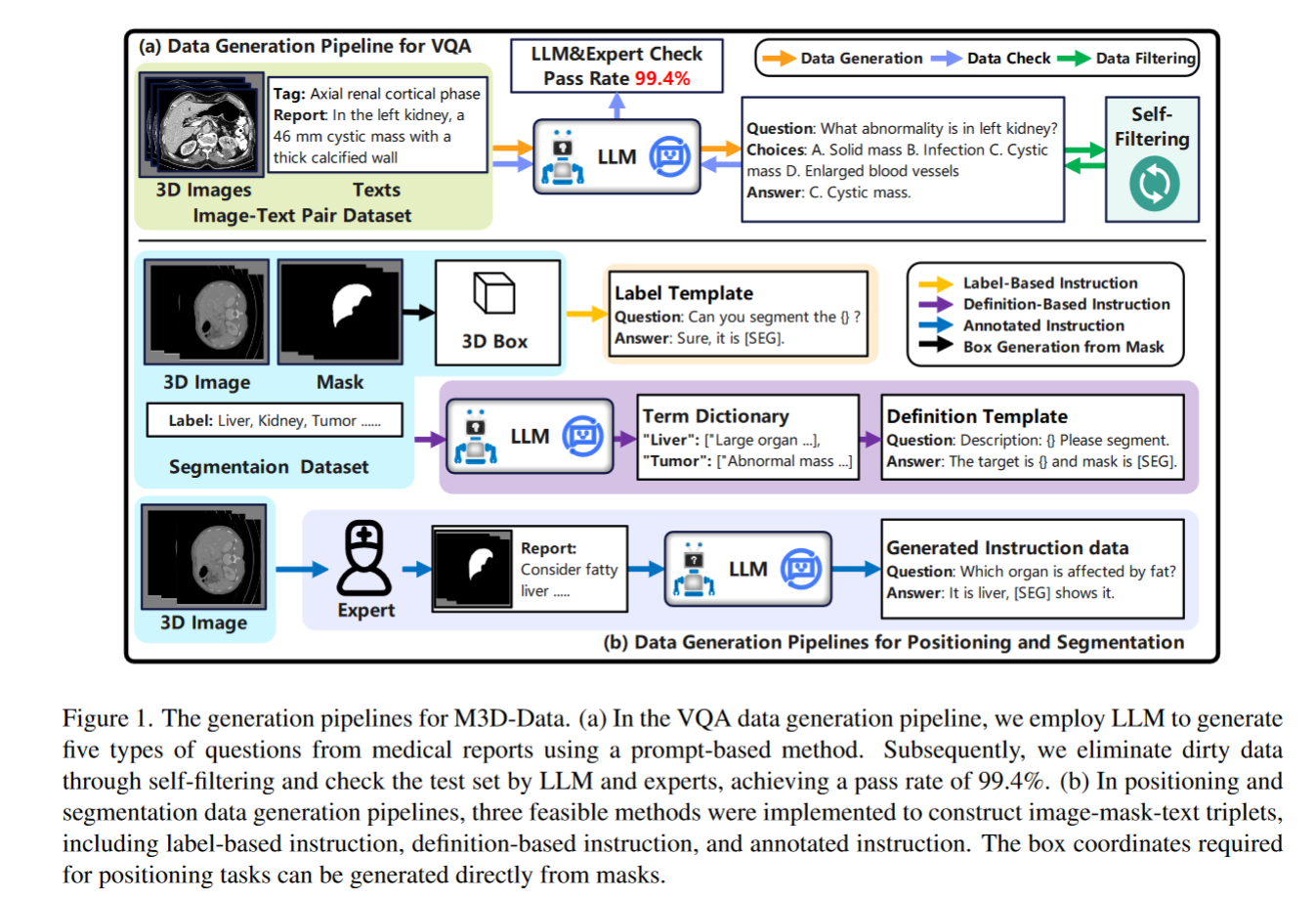
方法
训练了一个3D-ViT作为视觉编码器,同时对3D token又经过一轮spatial pooling降低维度
对于切割任务,根据seg特殊token最后一层的嵌入作为特征
评估和benchmark
1.image-text检索
看召回率,以及R@1,5,10
2.report generation
BLEU,ROUGE,METEOR,BERTScore和LLM(qwen72B)评估
3.VQA
4.定位
输出框 这里取输出框和真实状况IOU大于0.2视为正确
输入框,输出文字 BLEU, ROUGE-L, METEOR, BERT-Score
任务包含Referring Expression Generation和Referring Expression Comprehension
5.segmentation
任务包含semantic segmentation和referring expression segmentation
例子在附录中很完整,而且有样例
收获
1.各类prompt很齐全
2.segmentation和position任务的考察
3.报告生成的instruction,有十几种指令生成报告的特定部分
RadGenome-Chest CT: A Grounded Vision-Language Dataset for Chest CT Analysis
https://arxiv.org/pdf/2404.16754
以前:全局描述 —> 现在:区域描述 主要做的是胸部CT
数据集处理
原始数据集: CT-RATE
注: 一个study有findings和一个impression
切割图片: 使用SAT model(接受文字prompt)在整理的9个区域,197个解剖做提示切割
切割句子: 用gpt4标注数据然后训练gpt2模型对句子做切割,输入findings中的每一句话,输出一个判断结果标签(eg: 左肺)
对命名实体的处理: 对findings的每句话用NER模型分类(解剖,异常,非异常),提取到这些类别的短语或者句子,然后对异常和不异常的类别短语给gpt4进行过滤并且进行更细致的切割 —> ground-level
对impression部分做疾病提取切割 —> case-level
完整流程如图: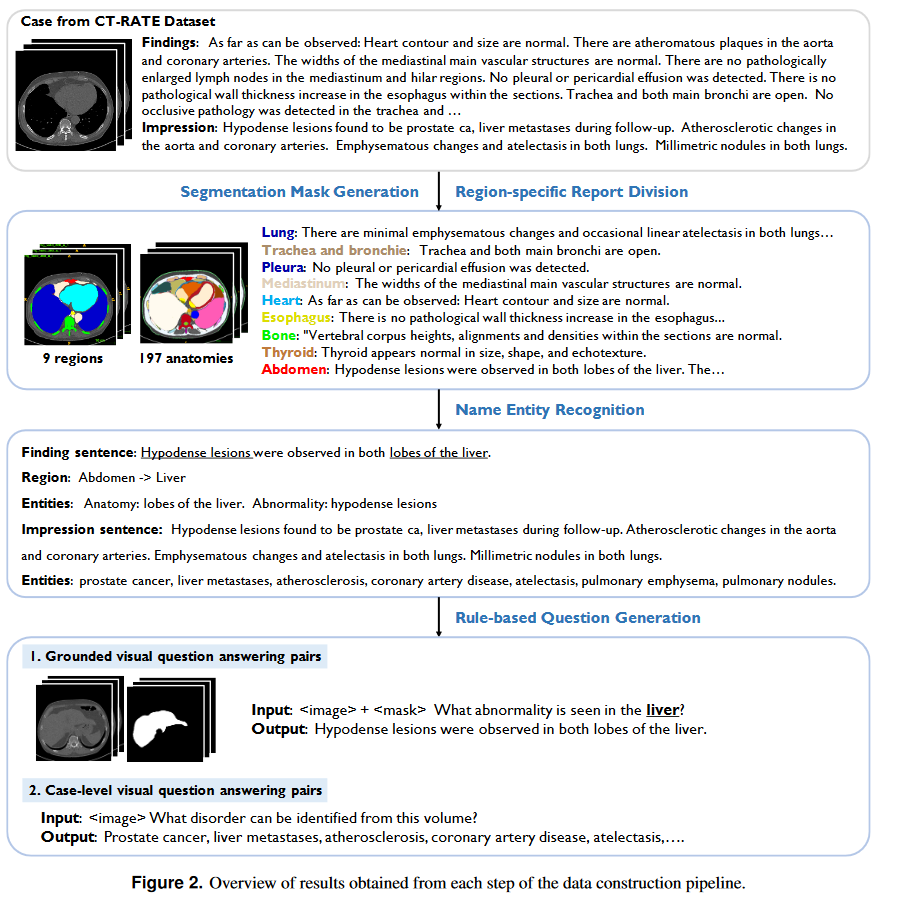
构造的5种VQA举例如图:
这里可以将问题分为四种类型:异常,存在(presence),位置,大小(每种问题50个模版)
AutoRG-Brain: Grounded Report Generation for Brain MRI
https://arxiv.org/pdf/2407.16684
代码没有开源,实现小细节未知
主要做的是MRI脑部,有6种模态 —> T1-weighted, T2-weighted, DWI, T2-Flair, ADC, T1-contrast
提出AutoRG-Brain
评估方式
1.全局报告生成 —> 三种方式
(i) AutoRG-Brain-Global:利用全局图像特征生成全局报告
(ii) AutoRG-Brain-AutoSeg:通过连接自动分割区域的接地报告来生成全局报告
(iii) AutoRG-Brain-Prompt:通过将接地报告与人工提示连接起来生成全局报告,即在结构分割结果上指定感兴趣的区域
2.grounded report generation
special 观点
一旦模型被训练,基于全局特征生成的报告就保持固定。而使用区域线索生成的报告可以通过人工提示或分割模型的改进来增强
方法
第一阶段: 训练分割模型—>使用医院里健康的样本
构造异常数据和标签:
1.先用带有脑结构标记和分割的MRI图谱映射到未标记的医院健康脑MRI数据上,获得这些图片的ground truth —> mark一下这里的EasyReg算法
2.随机选一个大脑结构,并计算Morphological Gradient检测结构的边缘,分成边缘和非边缘区域,选择它们的中心作为病变点
3.利用弹性变换生成形状
4.施加异常信号强度,根据选择区域的平均强度,最高强度,最低强度信号利用正态分布得到异常强度(可高可低)
5.将构造的异常替换正常的…涉及一些处理
使用nnU-Net作为分割模型,考虑dice和交叉熵损失,利用这里生成的数据训练分割模型(掩码图)
每个特定MRI modal的encoder不同,decoder共享
第二阶段: 冻结分割模型训练报告生成—>使用医院里健康的样本和开源数据集
(原始图像,掩码图,ground truth报告)三元组
这里需要对开源数据集处理,因为只有全局报告,使用训练好的分割模型分割图片,并且用gpt4提示分割报告中不同modal的内容,得到数据集
tip: 这里想考察全局,让掩码图全1即可,可以不用特意关心是否是ground还是全局
训练方法常规,不过这里直接使用了之前训练好的decoder和前三层decoder来embed输入
A ready-to-use machine learning tool for symmetric multi-modality registration of brain MRI
https://www.nature.com/articles/s41598-023-33781-0
MRI配准模型
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
https://arxiv.org/pdf/2306.00890
ni-Med: A Unified Medical Generalist Foundation Model For Multi-Task Learning Via Connector-MoE
https://arxiv.org/pdf/2409.17508
code
CMoE架构解决多任务拉锯战问题
选择的router network
1 Constant router, which assigns equal weight to each expert.
2 Hard router, which enforces one-to-one mapping between tasks and experts.
3 Sparse router, which selects Top-K experts with the maximum routing weight.
4 Soft router, which calculates the routing weights for each expert.