数学题benchmark论文合集
OMNI-MATH: A UNIVERSAL OLYMPIAD LEVEL MATHEMATIC BENCHMARK FOR LARGE LANGUAGE MODELS
https://arxiv.org/pdf/2410.07985
提出Omni-Math和Omni-Judge
数据收集: 从AoPS网站提取数据,多个答案相互比对
数据标注: 手动标注验证数据集的解决方案和答案
难度分级: 直接利用AoPS的难度评级,如果没有评级的比赛,用gpt4o
领域划分: 用gpt4o
验证: 对于生成的答案和标准答案格式不同的情况,采用gpt4o验证。同时训练一个Omni-Judge的评估模型,低成本评估模型解决方案和参考答案的一致性
分析实验中:
1.消除数据污染,n-gram准确性
2.judge模型准确性
3.不同领域,难度,相关度的数据上下文相互影响(这个测试任务mark一下)
问题与困惑
4.4没看懂
Can Language Models Solve Olympiad Programming?
https://arxiv.org/pdf/2404.10952
推理技术
1.reflection
2.RAG
方法: 包含语义知识库(cp-algs教科书)和情景知识库(USACO集合中的所有其他问题)
首先使用问题描述进行提示,并生成要用于检索查询的初始解决方案
这个初始解决方案和问题描述被输入到BM25检索函数中,最高排名的文档被插入到上下文中以帮助实际的解决过程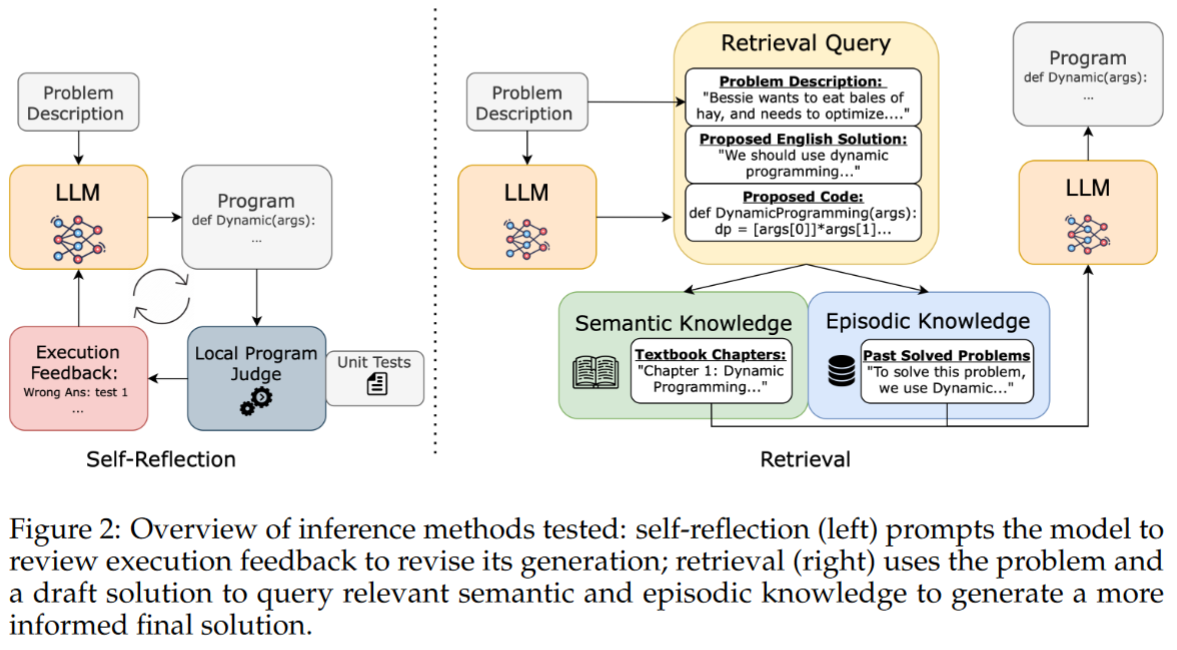
结论
情景检索和自我反思有很强的协同作用
性能提升不是由于记忆
问题与困惑
1.实验结论中Performance gains are not due to memorization.这个观点没有看懂为什么这样说
收获
1.reflection和RAG搜索过程的prompt写法
2.评估生成答案距离正确答案距离的方法
Competition-Level Problems are Effective LLM Evaluators
https://arxiv.org/pdf/2312.02143
使用codeforce的题目作为数据集
着重考虑的是解决未见复杂推理问题时的挑战
提到的一些参考文章可以后续泛读一下
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.