医学benchmark合集
MultiMedEval: A Benchmark and a Toolkit for Evaluating Medical Vision-Language Models
https://arxiv.org/pdf/2402.09262
code
现状是现有评估制度不统一,这里建立了统一基准
related work
几篇关于训练医学报告生成,VQA的论文需要看一下
任务
图像分类、问答 (QA)、视觉 QA、报告摘要、报告生成和自然语言推理 (NLI)
多类别图像分类:
除MIMIC-CXR数据集,模型的预测答案是通过计算模型响应与每个类别之间的BLEU分数来确定的,选择分数最高的类别
对于MIMIC-CXR数据集,我们在响应上使用CheXBert标记器,提取类别以后使用macro F1, macro AUROC, and macro accuracy评估
Question answering:
主要是选择题,是非题—>提取或者使用BLEU
visual question answering:
标记化预测答案和生成答案,用recall,F1等指标评估(封闭式和开放式问题对于recall的要求不同)
非标记化使用BLEU分数
report generation:
F1-RadGraph、CheXBert 矢量相似度、F1-bertscore 和 RadCliQ
n-gram方法: ROUGE-L、BLEU-1、BLEU-4 和 METEOR
report summarization:
指标同上
natural language inference:
矛盾类、蕴含类或中性类(近似于三分类问题)
要求给出两个句子的逻辑关系
收获
1.任务的评估指标和方法
2.提示各种数据集的prompt
GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI
https://arxiv.org/pdf/2408.03361
code
提供单选题和多选题的VQA benchmark,考察正确率和召回率两个指标(P40页有具体定义式)
benchmark要点
1.涵盖全面的医学知识
2.跨任务,跨科室的评估
3.多感知粒度的能力,全局到细节
当前的问题: 无法满足模式和任务多样性,无法反应实际临床实践,有数据泄漏的风险
benchmark构建方法
1.收集数据集,对图像2D/3D转为2D,对标签(病理结果,例如肺癌)进行处理,保证独一无二和清晰
2.标签分类和构建词汇树
根节点下面有三个主题: 临床VQA任务(18个),科室部门(18个)和感知粒度(4个)
个人理解: 一个图片和标签为一个叶子节点,归属于这些主题下面,中间的路径包含modality。三个主题是分开的主要任务
3.构建VQA
根据模态,临床任务,粒度三个方面选择标签并生成候选问题
全局视图和局部视图的处理情况不同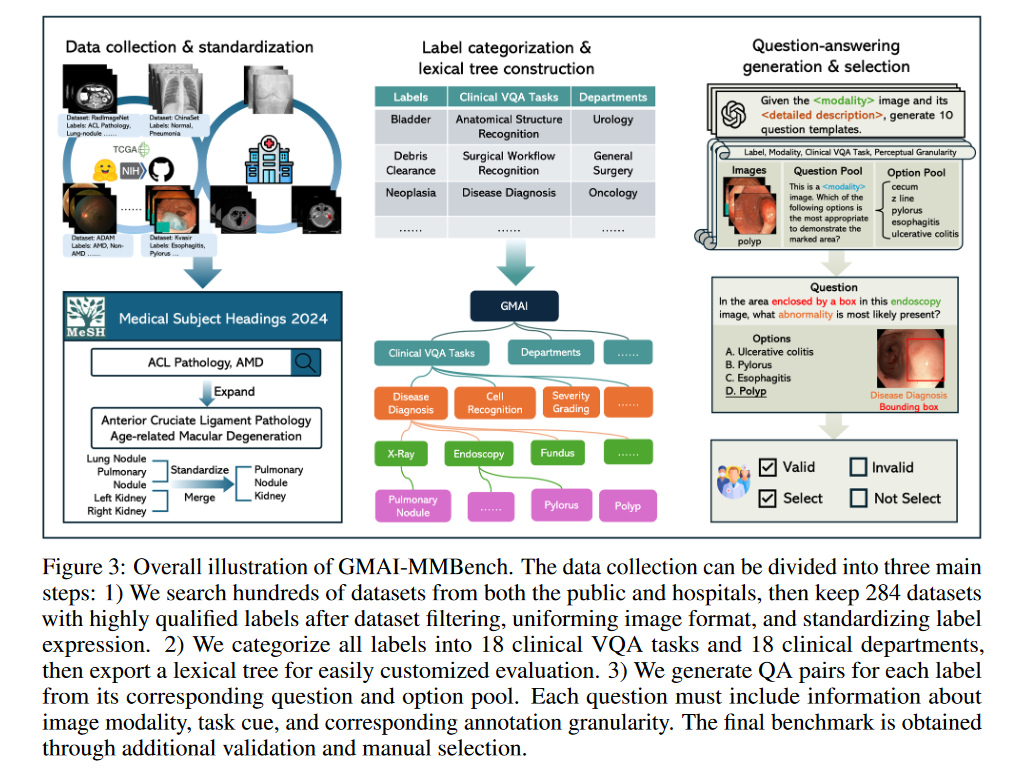
重要结论
1.基于通用模型微淘后的医疗专用模型性能很多还不如通用模型—>医学数据集质量有待提高
收获
1.提示VQA单选题和多选题的prompt instruction