ICL论文合集
In-Context Learning with Long-Context Models: An In-Depth Exploration
https://arxiv.org/pdf/2405.00200
code
长上下文ICL可能非常有效,但大部分收益来自于回顾类似的例子,而不是任务学习
实验
对比方法:
1.采样固定子集
2.检索每个示例的相关数据(使用BM25检索器)
3.对完整数据集进行微调(使用分类头?)
模型:
不同长度的预训练模型—>一般也选择这些 猜测原因:或许是这样更容易对比出结果
基础结论
1.更长的上下文会降低仔细选择上下文示例的重要性(随机/检索),检索相对于随机的优势随着例子增多不断变小
2.微调相比于ICL需要更多数据 —> 没啥意思
3.提供额外上下文输入可能会降低性能,但整体还是不断提升的
4.载所有上下文长度下对示例顺序都有一定的敏感性,但随着上下文的增加,这种影响会大大减弱
5.把相同标签的排序放在一起,随着示例增加,对性能有很大负面影响 —> 论证示例的随机分布对于保持模型性能的重要性
研究长ICL起作用的原因
实验设置: 修改注意力形式,用一个个块分割,只计算这些块的内部注意力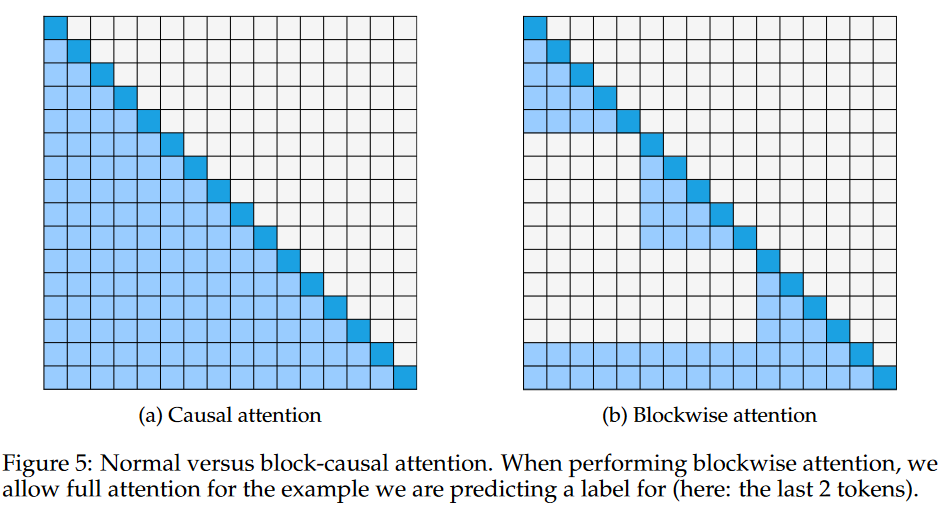
1.对比前提是使用相同的example集合 块的大小不断增加,性能提升(25-75左右达到95%的全注意力)
2.按照label区分块注意力,性能降低幅度没有比全注意力大 —> 模型的大部分性能提升并不是由于在每个块内学习决策边界并聚合它们。如果任务学习是主要驱动因素,那么模型需要多个类别的示例进行交互,才能形成更好的分类边界
3.最终结论: 长上下文建模的主要性能提升是由于从上下文中检索到更多相关的示例,而不是学习更好的任务边界
4.补充: 这里对0-shot下几乎没有正确率和1-10shot下没有提升的任务直接不考虑,会混淆结论得出
相关工作
待补充
疑惑与想法
1.论文的实验和结论有点跳跃—-这里探讨ICL是任务学习还是示例检索
文章中的意思:
如果长上下文ICL的提升主要是因为任务学习,那么块级注意力应该会显著降低模型性能:
因为如果任务学习是主要因素,那么每个示例都应该尽可能多地参考其他示例,来形成更好的任务表示。
限制示例之间的注意力范围,应该会阻碍模型学习到更复杂的任务模式。
但如果长上下文ICL的提升主要来自于示例检索,那么块级注意力的影响应该不会很大:
只要预测目标示例仍然能回溯到足够多的相关示例,它就能利用这些示例进行预测,而不需要全局信息。
但问题是任务学习 vs. 示例检索的界限并不清晰—-论文认为,如果任务学习是关键因素,那么减少示例之间的注意力范围应该会影响性能。但实际上,即使任务学习在起作用,也可能仅需要部分示例间交互,而不需要全局注意力。
换句话说,任务学习和示例检索可能不是完全对立的,而是互相影响的。
论文没有直接提供关于模型如何使用长上下文的细粒度分析(例如通过注意力权重或梯度分析)模型是否真的在利用示例检索进行推理?
块级注意力可以接近全局注意力的效果,甚至在某些情况下更优。但这只能说明全局注意力的收益有限,并不能直接否定任务学习的作用。例如,可能只是因为大多数示例在全局注意力下也不会有太多交互,导致减少交互不会带来很大影响。
Many-Shot In-Context Learning
https://arxiv.org/pdf/2404.11018
探讨两种shot方式下few-shot到many-shot的提升
Introduction
reinforced ICL: 使用模型生成的内容(经过答案过滤)得到shot
unsupervised ICL: 使用problem-only来作为shot
克服预训练偏差(表现与微调相当)
探索其他非nlp预测任务
scaling ICL
实验设置:
1.为了获得可靠的结果,使用不同的随机种子多次对每个K-shot提示的上下文示例进行随机采样,并报告平均性能,以及对单个种子的性能进行一些可视化
2.为了确保使用many-shot提供了额外信息,任何K-shot提示都包含少于K个示例的提示中的所有ICL shot
考察任务:
1.Machine Translation 冷门语言Bemba和Kurdish的机器翻译任务
2.Abstractive Summarization
3.Planning: Logistics Domain
4.Reward Modelling with Many-Shot ICL: Learning Code Verifiers
Many-shot Learning without Human-Written Rationales
reinforced ICL: 自我生成的结果虽然会有错误推理链得到正确答案的情况,但至少可以达到human-written的效果
unsupervised ICL: 一个假设是若LLM已经拥有解决任务所需的知识时,提示中插入的任何信息都可以缩小该任务所需知识的范围,会有帮助
问题解决任务(Problem-solving): MATH和GSM8K
1.与使用问题和解决方案相比,仅使用问题时,many-shot ICL可以实现相当或更好的性能
2.表明解决方案可能是多余的,这可能是由于在预训练期间看到了大量与数学相关的数据
QA任务
算法符号推理任务(Algorithmic and Symbolic Reasoning): 强化ICL都远远优于无监督ICL
分析many-shot ICL
1.many-shot可以overcome预训练bias,few-shot效果不行可能解释是检索到了错误的技能
2.非自然语言任务中例如高维二元线性分类,顺序奇偶校验(sequential parity)
3.many-shot ICL可以使特定于任务的微调变得不那么重要
4.many-shot的推理时间上可以用kv cache
5.通过重复示例作为many-shot的实验证明many-shot的提升在于添加大量新的信息
6.不同顺序下many-shot也有影响,有一个扩展是使用DSPy作为优化prompt的方式
7.负对数似然(NLL)未必能代表problem-solving领域上的表现,用ground-truth的ICL虽然NLL更小,但效果不如使用模型生成作为的shot
THE MECHANISTIC BASIS OF DATA DEPENDENCE AND ABRUPT LEARNING IN AN IN-CONTEXT CLASSIFICATION TASK
https://arxiv.org/pdf/2312.03002
ICL由induction head的突然形成所产生