视频图像推理调研
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs
https://arxiv.org/pdf/2312.14135
视觉搜索两大因素:
1.top-down feature guidance
2.contextual scene guidance
当前的问题:
1.基于预训练的视觉编码器分辨率低,需要把图片resize成低分辨率,忽视一些细节
2.无法识别缺失或不清楚的视觉细节,无法查找请求这些丢失的信息
提出SEAL架构,一个VQA LLM和一个视觉搜索模型组成,都是用llava初始化
设计V搜索算法模仿人类的视觉搜索
提出Vbench
总体架构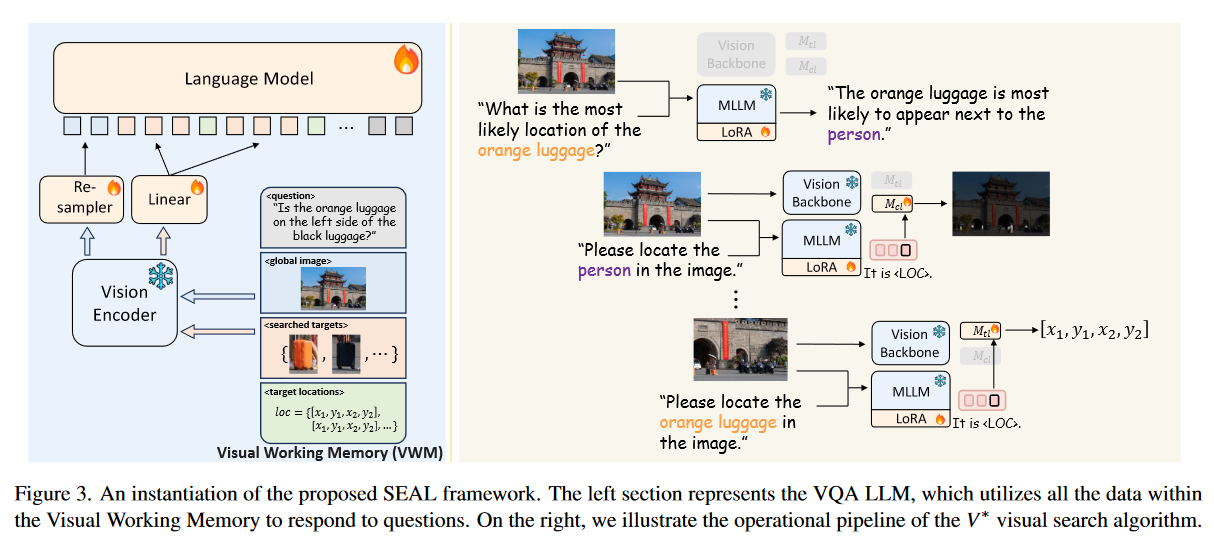
主要是VWM储存所需的内容,不断缩小图片进行搜索
注意点: 3.1最后提到视觉投射层使用linear projection或cross-attention based resampler projection
训练数据处理
negative data: 图像中不存在的物体以及无法被clip编码器捕捉的问题(20*20以内)进行提问,要求列出所有需要额外的目标物体 —- gpt3.5生成
VQA data: GQA; 属性理解VQA; 空间关系VQA
搜索方法
单次搜索:
1.输入固定格式的文本指令与图片,输出Loc token
2.Loc经过两个独立的mlp,得到$V_{tl}$和$V_{cl}$,前者用来得到坐标和置信度分数,后者用来得到heatmap

搜索框架: 仿照A-star方法
benchmark
考察两部分
1.attribute recognition
2.spatial relationship reasoning
COCO重新生成VQA构造的
可参考的内容
1.开放问题和封闭问题的格式
2.数据构建的prompt
3.训练细节
Plug-and-Play Grounding of Reasoning in Multimodal Large Language Models
https://arxiv.org/pdf/2403.19322
提出P2G方法和P2G benchmark
方法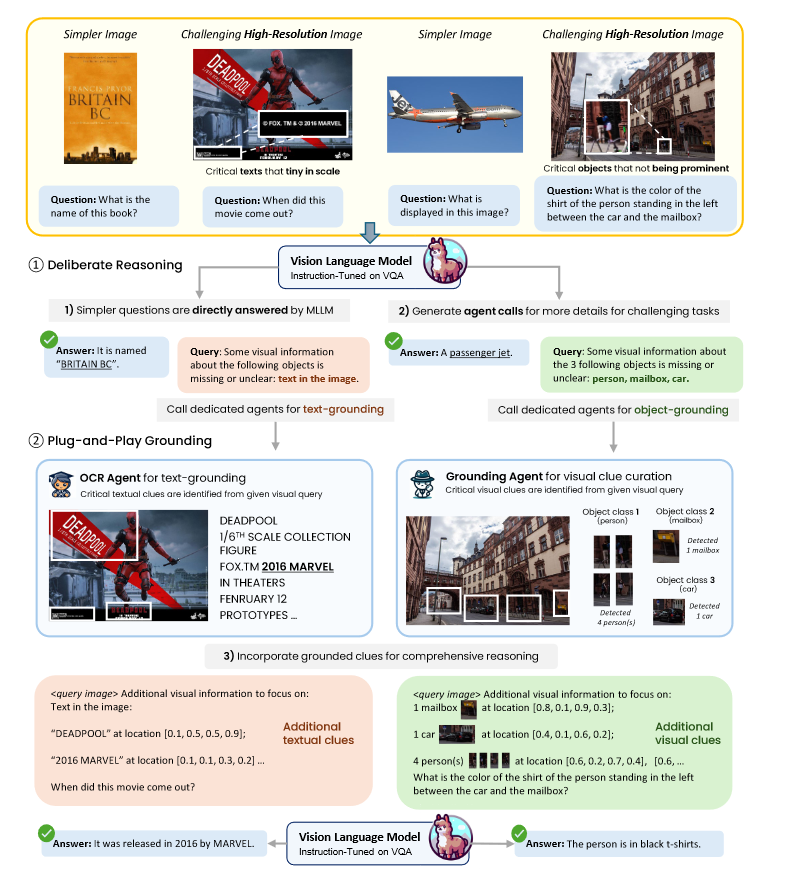
使用OCR agent(PaddleOCR)和grounding agent(Grounding DINO)即插即用的回答问题
第一步: 做常规的指令微调
第二步: 学习刻意推理(判断是否需要agent call和利用agent call)
任务有text-rich image reasoning和visual object grounding,也就是文本提取和图像识别
训练数据
1.llava指令数据集
2.ChartVQA, DOCVQA, TextVQA数据集 — 分辨率大于500,关键文本小于20的图像
3.V*数据集
4.SA-1B数据集构建benchmark
疑惑
1.为什么不用两个模型,一个判断是否要agent calls,一个学习如何利用agent call —- 可以考虑
2.文中说的两阶段是分开还是混合训练 —- 无所谓
HiRes-LLaVA: Restoring Fragmentation Input in High-Resolution Large Vision-Language Models
https://arxiv.org/pdf/2407.08706
使用了slicerestore adapter和self-mining sampler
使用self-mining sampler的原因: 之前的Q-former等压缩方式缺少位置信息,而且需要比较大量的训练数据
动态高分辨率切分: 设置一个最大切片数M,根据基础分辨率向上取整得到长宽数据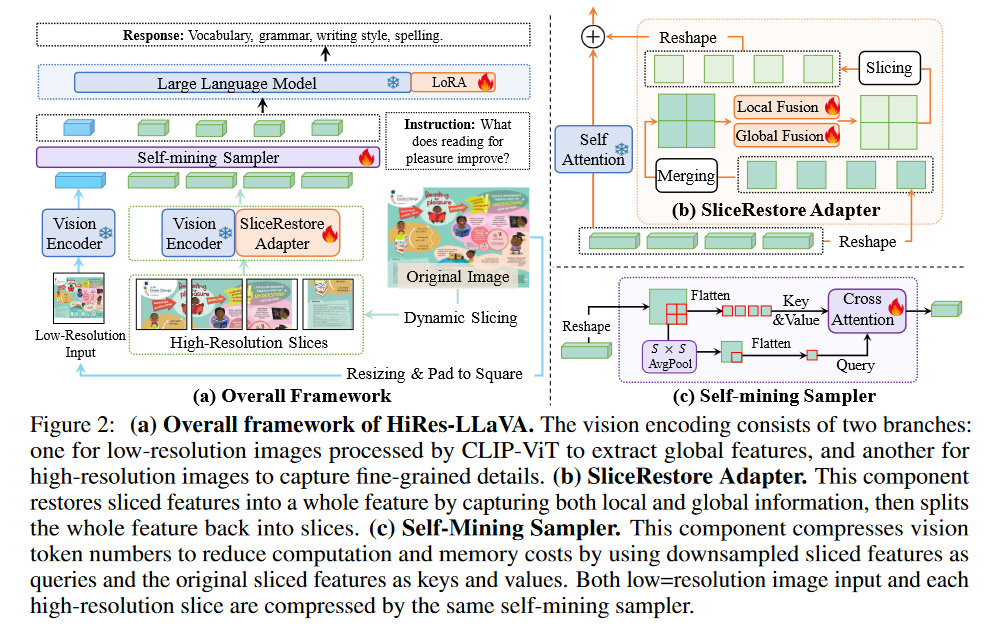
疑惑
1.很多地方感觉为什么这样使用不太懂
Imagine while Reasoning in Space Multimodal Visualization-of-Thought
https://arxiv.org/pdf/2501.07542v1
之前的方法: 两阶段策略/外部工具
问题: 利用文本描述图片这类可视化操作难以捕捉复杂的视觉模式和空间布局,而使用外部工具受限于工具本身的能力,而非提升模型本身的推理能力
一些相关概念: dual-coding theory
提出MVoT
Chameleon: Mixed-Modal Early-Fusion Foundation Models
https://arxiv.org/pdf/2405.09818
code
问题: 对不同模态进行建模限制跨模式集成的能力
提出混合模型Chameleon
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
https://arxiv.org/pdf/2412.14164
code
提出VPiT方法,可以生成离散文本token和连续视觉token
观点
这里需要好好关注一下分析方法
1.预测视觉token来源于理解视觉输入,这一能力只需要很少的额外训练就可以获得
2.视觉理解和生成是相辅相成的,增加任一功能的数据会同时增强两者
3.增加理解数据对两种能力的提升效果更显著,而增加生成数据虽然也能提高生成质量,但对视觉理解能力的提升效果相对较小
4.常规的、以视觉为中心的和文本理解的VQA任务与视觉生成表现出很强的相关性,而基于知识的VQA任务则不然 —> 用Pearson correlation来衡量
数据集
1.视觉理解 image: Cambrian-7M; video: ideoStar, ShareVideo
2.视觉生成 MetaCLIP
3.其他数据 SomethingSomethingV2, HowTo100M
Visualization-of-Thought, VStar
InstructPix2Pix, Aurora
这里的模版可以参考这篇论文里面的形式
benchmark
图像问答: MMBench, Seed, V*, MMVP, MMMU, ChartQA, TextVQA, ScienceQA, RealWorldQA
视频问答: MV-Bench
图像生成: FID Score, CLIP Score
模型架构和训练方法
文本头和视觉头同时生成,通过special token来区分选用哪一种形式的token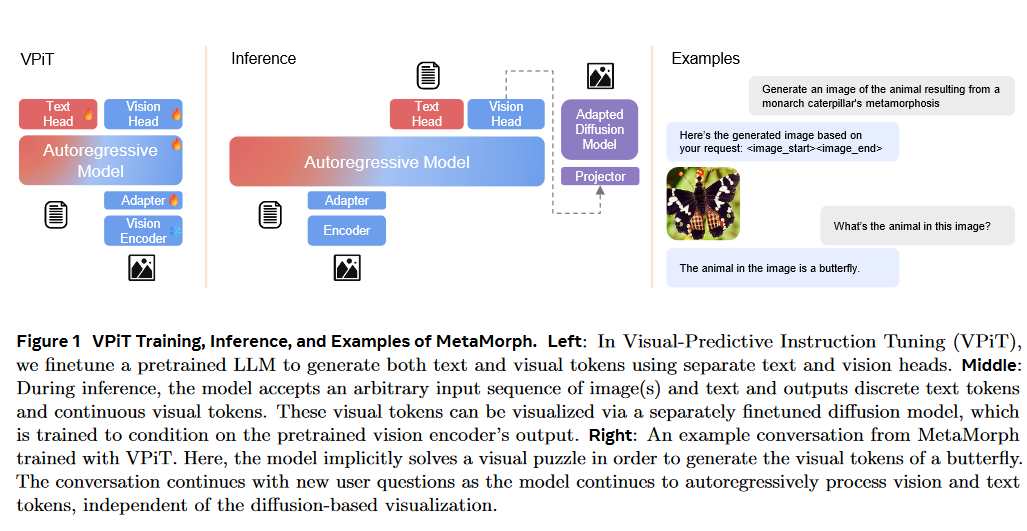
loss设计:
1.图片生成使用GT图片经过视觉编码器得到的特征向量与vision head生成的特征向量计算余弦相似度
2.文本生成的交叉熵损失
From the Least to the Most: Building a Plug-and-Play Visual Reasoner via Data Synthesis
https://arxiv.org/pdf/2406.19934
提出了least-to-most视觉推理范式
提出了完全基于开源架构的数据合成方法,构建50k的VIERO数据集
least-to-most视觉推理
4种工具: grounding和highlight使用GroundingDino, OCR使用PaddleOCR, Answer使用VLM
数据合成方法
蒸馏gpt4v代价高,难以复制,推理效果不够好
1.entity recognition 用Deformable DETR检测识别,提取标签和位置,这里过滤掉置信度小于0.5的标签
2.node construction 单实体节点生成文本描述: label, location(边界框), color(colorthief提取), text(PaddleOCR), size(面积)
实体组使用BLIP模型生成文本,描述实体之间的关系
全图节点用llava生成全图描述
3.Reasoning process Synthesis
疑惑
1.这里使用llava生成全图,BLIP生成部分图 是不是不够准确,这样的数据质量受限于llava本身的能力吧
2.这篇文章总体上效果很烂,只有调用工具的方法有些可以参考的地方
Video-of-Thought: Step-by-Step Video Reasoning from Perception to Cognition
https://arxiv.org/pdf/2501.03230
code
视频推理: 像素理解的感知能力(细粒度),语义理解的认知能力(利用常识),从低到高多跳的流程
提出MotionEpic框架
STSG
均匀采样视频帧,这里猜测应该是一张张图生成STSG,然后再用一些方法把跨帧相同的物体关联起来(可能是一些跟踪算法?)
- SG: 表达静态图像或单帧视频中的语义内容
每一个帧由点集合和边集合组成,一个点包含物体分类标签,特征表示和b-box,边是物体之间的关系(例如在上面) - STSG: 关联跨帧的相同物体
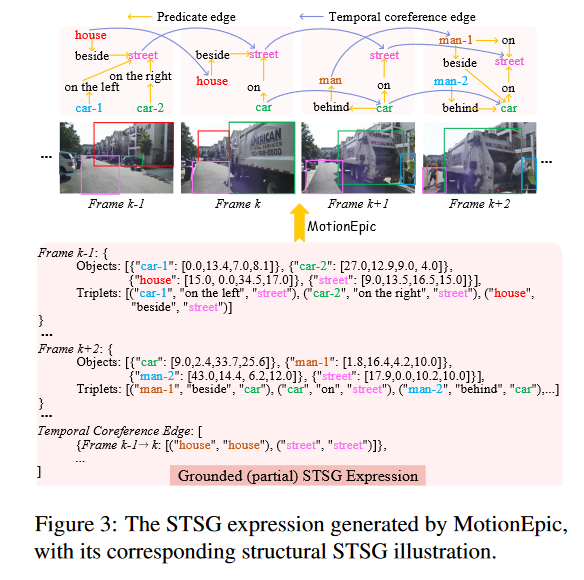
训练STSG生成
1.粗粒度训练(Coarse-grained Training)
L1: 视频与STSG是否匹配
L2: 从视频生成整个STSG表达式
2.细粒度训练(Fine-grained Training)
L3: 给定一个视频和与之相关的动作描述,模型需要生成对应物体的轨迹
L4: 给定视频和关键物体的情况下,生成描述物体动作的时空信息,并输出对应的轨迹
L5: 给定某一帧视频和物体的边界框时,输出物体的标签以及其时空轨迹
整体推理流程
推理流程:
1.目标识别
2.物体追踪—生成STSG格式
3.动作分析
4.回答问题,从高到低排序
5.答案确认(不确认回到第四步)
数据集
训练STSG生成: Action Genome, WebVid-10M
进一步对齐: VideoChat, Video-ChatGPT
benchmark: VLEP, STAR, IntentQA, Social-IQ, CausalVidQA, NExT-QA, MSR-VTT, ActivityNet(最后两个是zero-shot)
收获
1.open-end和选择题的完整5步推理prompt可以学习,这些方式的推理模版大多格式固定
2.5-step reasoning的方式
疑惑
1.这里怎么使用这些benchmark还有待考察,有些可能要给shot
2.训练准确生成STSG的过程文中说的比较简略,loss1-loss5看得一头雾水
3.这里使用graph transformer来对STSG进行encode操作,graph transformer还未了解过
DIVING INTO SELF-EVOLVING TRAINING FOR MULTIMODAL REASONING
https://arxiv.org/pdf/2412.17451
code
提出M-star自我进化训练框架
数据集
MathV360K中750条作为域内测试(一半用来训练),MathVista中testmini作为域外测试
训练方法
未完待续~~~
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Tong_Eyes_Wide_Shut_Exploring_the_Visual_Shortcomings_of_Multimodal_LLMs_CVPR_2024_paper
模型缺陷—很简单的问题回答错误—认为来源于视觉表示
这里定义CLIP-blind pairs是具有相似CLIP嵌入但具有不同DINOv2嵌入的图像
构建9个方面的MMVP benchmark,其中7种无法通过scale来解决
探索整合自监督视觉模型DINO
MMVP benchmark构建过程
原理: 两张图片有明显视觉差异,但是CLIP编码成相似的编码,其中一张图片必然是被模糊编码的(ambiguously)
1.找CLIP-blind pairs CLIP 嵌入的余弦相似度超过 0.95,DINOv2 嵌入的余弦相似度小于 0.6
2.设计问题 手动查明视觉编码器忽视的细节—-设置简单的问题
3.结果 只有当一对图像的两个问题都对,才认为正确—-注意这里对比human/random/model,并且需要做消融实验例如交换选项,更改问题确定这个问题来源于视觉障碍
CLIP的问题
1.用gpt4来分类
2.对CLIP进行scale,视觉模式表现有限
3.对比CLIP的表现和使用CLIP的MLLM之间表现的相似性(用Pearson Correlation Coefficient)
注意对CLIP的衡量直接用图片的视觉编码和两个答案(eg 狗在左/右)经过的文本编码计算相似度
Mixture of features提升
1.将CLIP和DINOv2以一定比例融合—-visual grounding提升,指令跟随下降
2.将CLIP和DINOv2交错嵌入
收获
1.构建benchmark的完整流程
2.文中总结的9中视觉模式可以参考
Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
https://arxiv.org/pdf/2405.10292
code
推理框架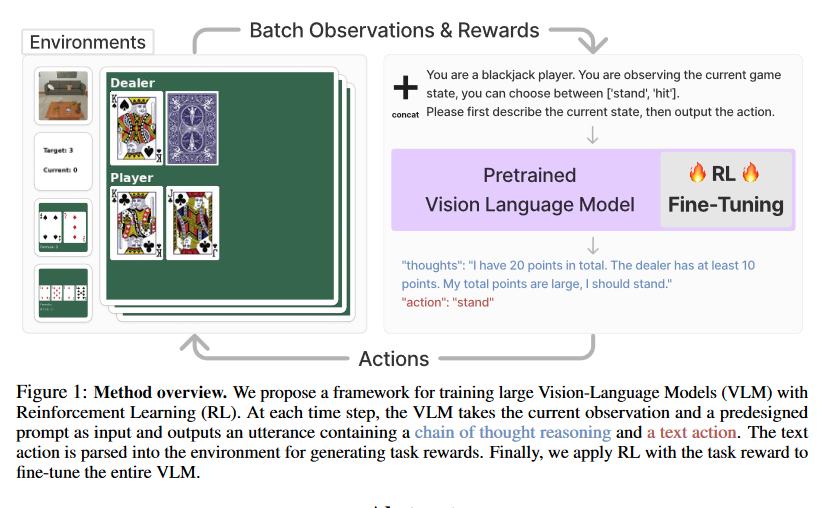
RL设计
1.根据提取的action做动作,如果action是不合法的,就从范围内随机抽以体现random exploration
2.
这个概率推导式这样设计原因是不能过于重视前面的推理内容,如果不加上这个超参数$\lambda$,效果会很差
考察任务
gym_cards(纸牌游戏)和alfword(具身环境)
疑惑与想法
1.这里使用的强化学习框架太人为化,对于不同的游戏都需要不同的prompt来提示,而不是单纯next-token prediction
以P21为例,那么多动作以文字的方式做选择效果好吗
Slow Perception: Let’s Perceive Geometric Figures Step-by-step
https://arxiv.org/pdf/2412.20631
code
总结: 算是一篇找不能做的任务自行构造数据集和优化,所谓慢思考也不是模型自主的行为而是外部人为操控的
目的: 解决geometric parsing任务,因为这个任务无法用目标识别算法来解决
方法: 提出两阶段slow perception—-感知分解(perception decomposition); 感知流(perception flow)
构建了一个几何图形数据集,可以很容易获取每一个点的位置和坐标
感知分解就是分解成所有线条和圆
感知流就是根据标尺长度设置推理方式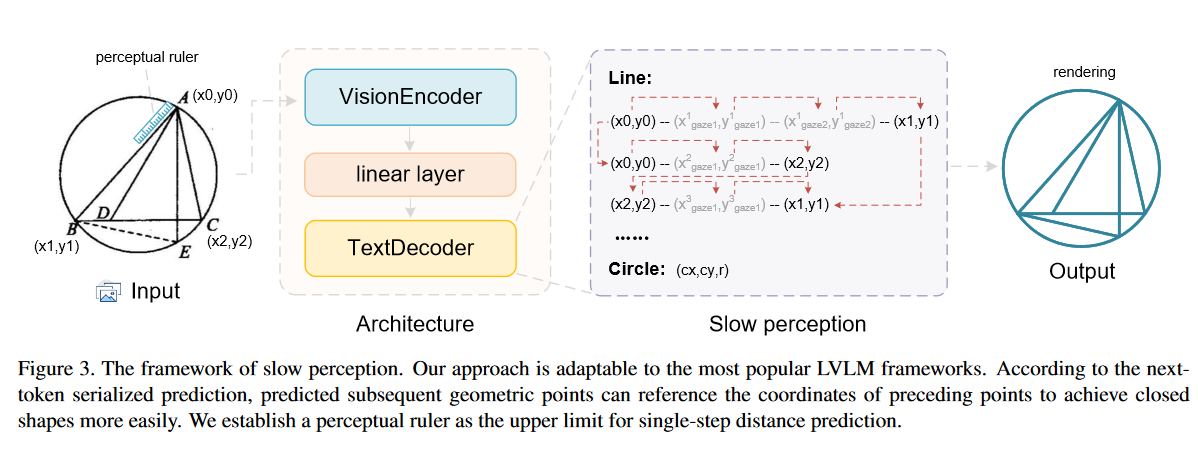
训练方法: 根据标尺长度,训练数据输出不同
疑惑与想法
1.为什么图1的例子无法用传统目标检测解决
2.这篇论文应该就是提出一个当前mllm无法做的事情
3.这里相当于是在不同标尺下,根据不同标尺长度来输出,由于输出的是文本,提升上限有限
Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
https://arxiv.org/pdf/2411.10442
发现问题: 开源mllm在使用cot时性能反而下降—-distribution shift现象
提出数据构建pipeline
数据构造方法
1.有ground truth的题目—-构造格式+答案正确的偏好
2.对没有ground truth的题目—-构造NTP,有图片作为输入的偏好—-截取pre answer一半的生成内容,不给图片往下生成得到dispre answer—-为了构造幻觉偏好
好处: 比之前的M3CoT更高效
训练方法
三部分组成
preference loss—DPO, quality loss—BCO, generation loss-SFT加权
Temporal Preference Optimization for Long-Form Video Understanding
https://arxiv.org/pdf/2501.13919v1
code
Vision language models are blind
https://arxiv.org/pdf/2407.06581
code
提出了7个测试,表明mllm在处理低级视觉任务的局限性
建议改进视觉信息处理的方法,以提高模型的视觉理解能力