多模态可解释性论文合集
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
https://arxiv.org/pdf/2311.17911
code
关键观察: 幻觉问题与自注意力矩阵中的知识聚合模式密切相关,MLLMs往往通过关注少数几个总结性token来生成新token,而忽视了图像tokens的完整信息,导致幻觉的产生
其中许多幻觉内容的开始与柱状注意力模式后生成的后续标记一致,而且往往体现在句号这种缺乏信息的token上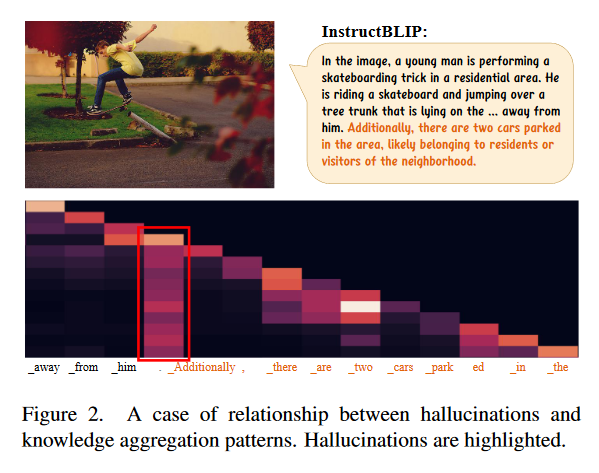
- 聚合模式似乎是LLM的本质 LLM倾向于聚合浅层的一些anchor token的先前信息,并根据深层的这些锚标记预测下一个标记
- 聚合模式导致幻觉 当前的MLLM通常将vision token放在序列的开头,并且期望它们专注于vision token并提供精确的理解。然而随着生成的文本越长,摘要标记之间的信息传递过程中视觉信息就越容易衰减 出现summary token越多,越容易触发幻觉
提出了OPERA方法缓解MLLM幻觉,这个方法基于beam-Search
方法
两个方面:
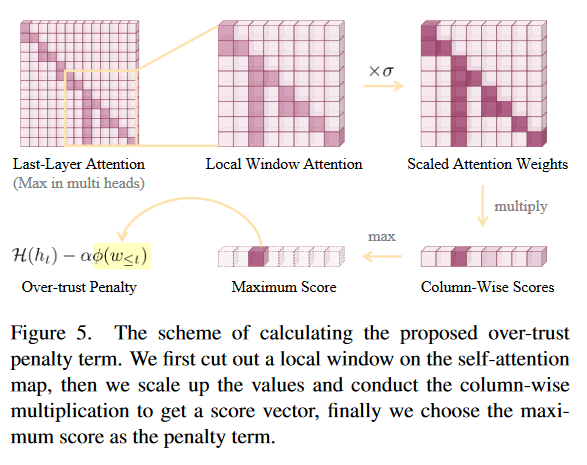
over-trust logit penalty
选择一个注意力窗口k,然后计算纵向注意力分数乘积的最大值选择判断为summary token
$\omega_{i,j}$代表第j个token对第i个token的注意力影响这里Y是beam search下所有候选token的集合,n个beam,m个candidate,集合大小就是m*n
Retrospection-Allocation Strategy
存在少数情况所有候选者都受到惩罚,幻觉已经发生
在连续的时间窗口下,注意力重叠次数大于某个阈值。触发summary token位置的重新生成(并且不生成之前的summary token)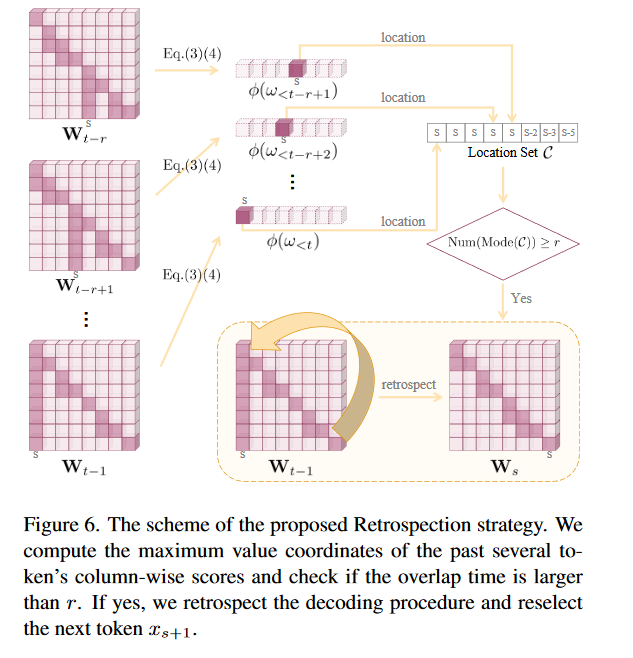
搜索方法
greedy, nucleus, beam search, DoLa(为了降低幻觉)
benchmark
在MSCOCO数据集上CHAIR, POPE判断视觉生成幻觉
PPL(perplexity)和GPT-4评估文本生成的质量
GPT4v评估生成描述的准确性
MME和MMBench评估性能
收获
1.几种解码方法的对比,和性能评估对比
2.多维度的评估方法
疑惑与想法
1.图3是怎么看出来的
2.图4的CHAIR分数是什么
3.相关工作还可以关注一下
4.当前的MLLM通常将vision token放在序列的开头,真的有这个说法吗
Paying More Attention to Image: A Training-Free Method for Alleviating Hallucination in LVLMs
https://arxiv.org/pdf/2407.21771
幻觉来源于模态对齐
这里提出一种场景,即使当图像输入被删除并且仅保留幻觉对象词之前生成的文本时,VLM仍然会产生相同的幻觉描述—-text inertia
提出假设当前的生成范式将图像表示映射到文本表示空间作为文本token,并提出PAI方法缓解问题
方法
两种方法:
- 提升图像注意力
直接提升图像token关于最新生成的文本token的注意力不过这里不是对所有的注意力头都提升,主要对本身注意力高的头提升,注意力低的头减少干预
attention sink pattern现象: 在浅层不明显(关注语义信息),在深层会提升(语义信息问题,注意力池现象增加),出现原因是冗余注意力(STREAMING)
- 图像为中心的logit修正
用来减轻幻觉
benchmark
1.CHAIR
2.POPE
3.MMHal-Bench
4.GPT-4v Assisted Evaluation—附录有evaluation的prompt
这里考察不同解码方式(本文的PAI, OPERA, VCD 常规解码有greedy, beam search, nucleus sampling),单轮/多轮对话
疑惑与想法
1.为什么要对注意力头低的减少干预
2.这里也是只有对超参数的消融实验,而没有对方法的有效性更深层面的解释—-确实
3.这篇文章比较清晰,选取的引用文章可以看看
Cross-modal Information Flow in Multimodal Large Language Models
https://arxiv.org/pdf/2411.18620
使用attention knockout策略抑制跨模态的信息流—-通过有意阻塞计算过程中不同组件之间的特定连接,通过观察最终预测概率的变化来追踪它们内部的信息流
任务考察
ChooseAttr:选择属性问题(例如,选择一个物体的属性,如“门是木制的还是金属的?”)
ChooseCat:选择类别问题(例如,选择物体所属的类别,如“床和门哪个有条纹?”)
ChooseRel:选择关系问题(例如,询问物体之间的空间关系,如“门在床的右边还是左边?”)
CompareAttr:比较属性问题(例如,比较两个物体的共同属性,如“自行车和狗有什么相同的?”)
LogicalObj:逻辑推理问题(例如,询问图像中是否存在某种物体,如“图像中有跑步的男人或女人吗?”)
QueryAttr:查询属性问题(例如,询问图像中某个物体的位置,如“狗在图像的哪一部分?”)
实验1
主题: 研究不同模态对最终预测的贡献
方法: 分别阻断last/question/image—-last
结论: 输出主要来源于输入的组件,而非自己; question的影响更加大
实验2
主题: 研究图像信息与问题的关系
方法: 阻断问题关注图像
结论: 图像的信息流对问题的流(flow)有两次,发生在第0-4层和第10层
实验3
主题: 视觉和文本信息如何整合
方法: 把patch分为与问题相关/不相关(根据数据集中的b-box)
结论: 初步的信息融合发生在较低层次,而精细的信息融合则在较高层次发生
实验4
主题: 研究答案如何生成
方法: 对每一层的隐藏层做softmax得到词表上的概率分布?
结论: 在中间层的时候从语义得到答案,之后开始细化语法(根据首字母大小写判断)
疑惑与想法
1.这里直接对每一层的隐藏层引用softmax合理吗,矩阵是最后一层的吧—-确实不够合理,但是目前没有更好的方法来做next-prediction分布,一般如果在最后几层用不会被质疑
2.根据首字母是否大写/小写开头来判断细化语法是不是有点草率—-确实不够solid
EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
https://arxiv.org/pdf/2309.17453
code
发现了attention sink的现象: 来源于window attention一旦上下文长度超过训练的context length,PPL就飙升
提出LLM streaming方法—-应用无限长度的输入但不会损失性能
对比dense attention, window attention, sliding window, streamingLLM
无限输入的两个挑战: 解码存储的k,v cache增加延迟; 外推能力有限,性能下降
attention sink: 大量注意力分配给初始token,无论他们和任务关系有多大
https://zhuanlan.zhihu.com/p/659893750
https://zhuanlan.zhihu.com/p/659875511
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
https://arxiv.org/pdf/2306.03341
code
Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
https://arxiv.org/pdf/2305.14160
探究ICL的内在工作机制
显著性分数saliency score
metric
考察三种metric,用显著性分数计算平均影响。这样可以得到信息流
其中label是文本中包含类别的标签,target是final token in the input
- text—-label
- label—-target
- 前两者剩余的部分

基于以上metric提出假设: 在浅层中,标签词从演示示例中收集信息以形成更深层的语义表示,而在深层中,模型从标签词中提取信息以形成最终的预测
验证假设
从浅层和深层两方面论证
浅层: 信息聚合
把text to label的attention前5层和后5层分别设置为0,评估label loyalty和word loyalty深层: 信息提取
这里使用AUC-ROC指标: 衡量模型在深层中的注意力分布与最终预测结果之间的相关性
应用
1.学习一个参数来做anchor token注意力的重新调整
2.压缩加速推理,这里合并格式和标签词的hidden state作为输入
3.通过anchor distance来检查错误
疑惑与想法
1.文章这里提到的情感分析解决的是什么样的任务,AUC-ROC评估的是模型预测能力
2.这里提到压缩token需要加上格式,否则无法完成ICL
3.论文3.3还未看
ON MEMORIZATION OF LARGE LANGUAGE MODELS IN LOGICAL REASONING
https://arxiv.org/pdf/2410.23123
code
结论: LLMs在逻辑推理任务中同时依赖记忆化和推理能力
Backward Lens: Projecting Language Model Gradients into the Vocabulary Space
https://arxiv.org/pdf/2402.12865
提出了backward lens
探究语言模型如何在训练过程中存储和修改知识
是否可以将梯度投影到词汇空间,从而解释模型如何存储和更新知识
Transformer的MLP层如何存储知识,是否可以在不计算完整梯度的情况下,仅通过前向传播实现模型知识的编辑
是否存在某种系统化的梯度更新模式,使模型能够存储和回忆知识
backward lens
相比于之前的工作只分析前向转博中的logit lens,只能解释隐藏状态和静态权重,而无法解释梯度如何影响学习
观察反向传播过程中的梯度,并使用logit lens方法将其投影到词汇空间
1.证明了梯度矩阵是low-rank的,根据反向传播公式梯度矩阵相当于两个一维向量的外积,秩最大为1
推导如下:
多个token情况下x和$\delta$正交
2.梯度对模型的影响
梯度在FFN层的传播模式显示出imprint与shift机制:
Imprint: 在FF1,梯度主要调整输入token的特征,使其未来更容易激活
Shift: 在FF2,梯度主要影响输出,使得预测结果更偏向目标token
相关工作
logit lens在隐藏层以外的地方的使用—-静态权重,FF1和注意力矩阵
logit lens的变种