agent方向论文调研
考察的问题
1.目前看到的论文大多与RAG相关,所以首先关注知识库构建的来源,提供哪些查询方式
2.如何融入查询的过程(联想到一些长下文的工作),提供的知识库引入方式有special token—-prompt/sft
3.对于复杂的任务进行分解
4.o1模型中提到的critique和refinement,目前没有看到这样的工作。比如提取到一个知识库之后发现没法很好的解决问题,然后进行回退
Search-o1: Agentic Search-Enhanced Large Reasoning Models
https://arxiv.org/pdf/2501.05366
code
motivation: 长思维链导致过度思考和增加知识不足的风险,在推理过程中高频的prehaps表明缺乏知识
这篇文章涉及到的触发检索是以prompt形式完成的

疑惑与想法
1.如果想触发检索,是不是用一些高质量数据做监督微调更好,让模型自适应的学会去查询什么信息,这里可以考虑构建一个pipeline—-具体这里怎么去实现
AGENTGYM: Evolving Large Language Model-based Agents across Diverse Environments
https://arxiv.org/pdf/2406.04151
方法: 先模仿学习预热,再用RL
推理: 先生成thought,然后action
疑惑与想法
1.之前看过的一些具身任务似乎和这里面的数据轨迹有点类似,当时这里有考虑多模态的情况吗
KBQA-o1: Agentic Knowledge Base Question Answering with Monte Carlo Tree Search
https://arxiv.org/pdf/2501.18922
当前的问题
1.知识库环境感知差
现有的端到端方法直接利用语言模型生成逻辑形式,难以完全捕捉知识库环境,特别是在遇到未知的实体和关系时
2.效率和效果的平衡
现有的基于CoT和ToT的逐步方法容易陷入局部最优或面临巨大的搜索空间,导致推理过程效率低下?
3.对标注数据的高依赖性
知识库来源: Freebase
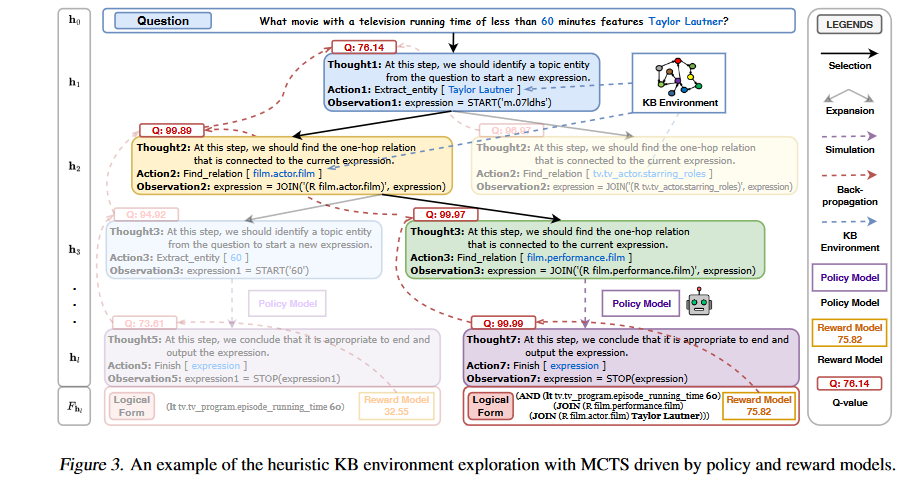
疑惑与想法
1.function call能力,如果调用外部工具,可能理想的情况下是输出json
2.这里用mcts的搜索空间是不是太大了
3.reward model是怎么训练的
Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
https://arxiv.org/pdf/2405.10292
code
推理框架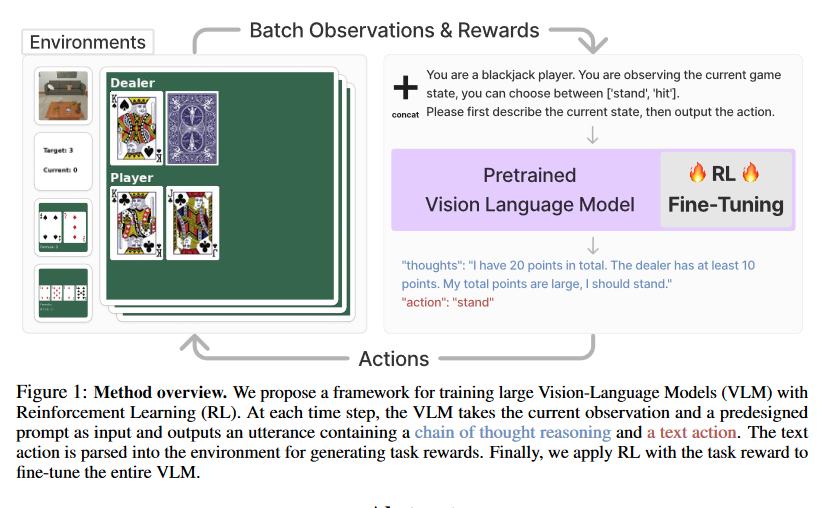
RL设计
1.根据提取的action做动作,如果action是不合法的,就从范围内随机抽以体现random exploration
2.
这个概率推导式这样设计原因是不能过于重视前面的推理内容,如果不加上这个超参数$\lambda$,效果会很差
考察任务
gym_cards(纸牌游戏)和alfword(具身环境)
疑惑与想法
1.这里使用的强化学习框架太人为化,对于不同的游戏都需要不同的prompt来提示,而不是单纯next-token prediction
以P21为例,那么多动作以文字的方式做选择效果好吗